Mixture-of-Experts Models for Claim Frequency and Severity
CAS RPM, March 15, 2023, San Diego CA
Actuaries: GLM Is Great!
GLM is simple yet powerful.
GLM is easy to implement.
GLM is interpretable and accessible.
However, GLM can fail miserably in insurance applications, because real data do not satisfy GLM assumptions.

GLM Fails when…
Claim frequency distribution is zero-inflated.
There is an excess probability of zero claims.
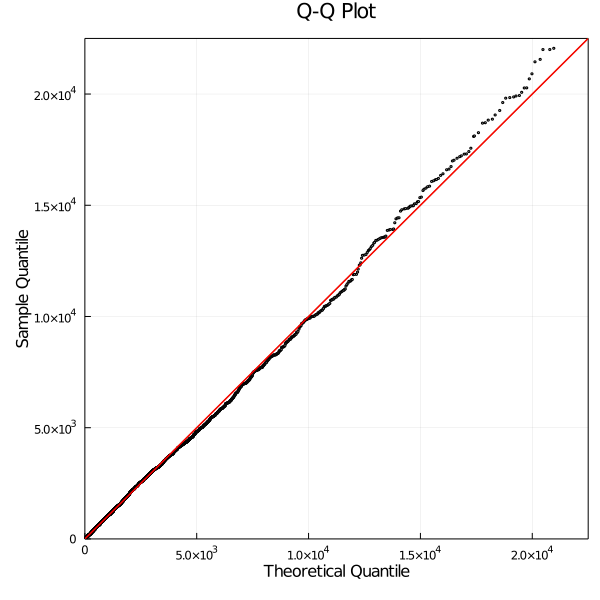
Example: Australian auto insurance data (ausprivauto040) in CASDatasets (Dutang and Charpentier 2020), GLM fit vs. empirical.

GLM Fails when…
Claim severity distribution is multimodal and/or heavy-tailed.
Observations are censored and/or truncated.
Example: French auto insurance data (freMTPLsev) in CASDatasets (Dutang and Charpentier 2020).

Insurance Data Are Heterogeneous
- Policyholders’ risk profiles are different even within the same portfolio of, e.g. auto insurance or home insurance.
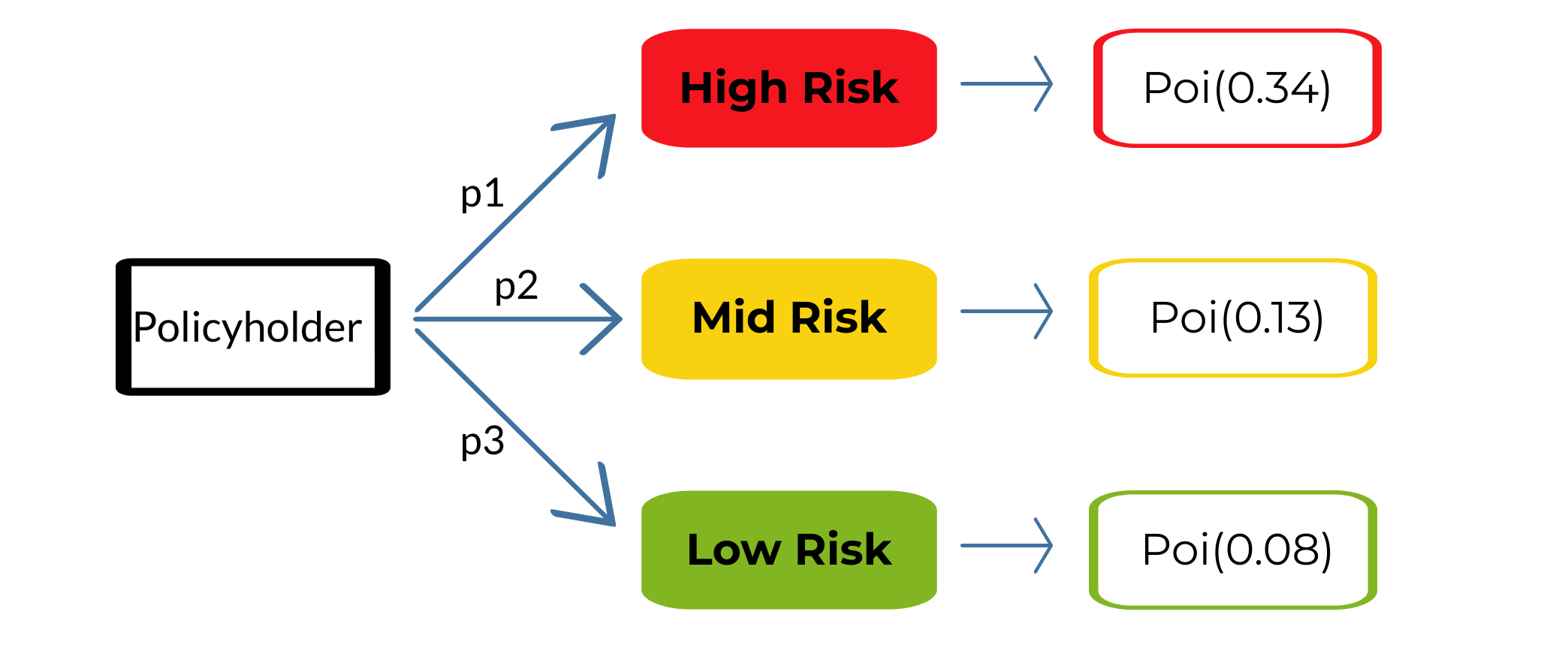
- One way to capture such heterogeneity is to use a mixture model.
Example: Modelling claim frequency with a 3-component Poisson mixture.
Covariates Are Important
- Policyholders’ information, or covariates, are predictive of their risk profiles.
- We may use regression to classify policyholders into different risk groups, and model each of these more homogeneous groups separately.
Example: A Poisson mixture model combined with logistic regression.

MoE = Regression + Mixture
Here is an example on how to incorporate covariates into the Mixture-of-Experts (MoE) framework.
- Based on the covariates, we first classify policyholders into different latent risk groups with a logistic regression.
- Within each risk group, we model the response (frequency or severity) with an appropriate distribution.
MoE: Flexible and Powerful
- The MoE framework can catch three patterns: regression, dependence, and distributional.
- For example, it offers a much better fit to data compared with GLM, as it can capture the nonlinear relationship between covariates and losses.
Example: Australian auto insurance data (ausprivauto040) in CASDatasets (Dutang and Charpentier 2020). Analyzed in (Badescu et al. 2021), LRMoE provides a better fit than GLM.

MoE: Flexible and Powerful
Example: French auto insurance data (freMTPLsev) in CASDatasets (Dutang and Charpentier 2020). Analyzed in (Tseung et al. 2021), LRMoE can provide good fit to data exhibiting multimodality.

Example: 3-Component LRMoE

1. Frequency and Severity
Our introductory examples on the Australian (ausprivauto040) and French (freMTPLsev) auto insurance datasets have already demonstrated the superior fitting performance of LRMoE compared to GLM.
- Australian: 3 components of Poisson
- French: 6 components of zero-inflated Lognormal
Question: What expert functions (distributions) should one use?
Comparing Sample Policyholders
Policyholder A: Lots of undesirable risk characteristics but no claims are observed during the contract period.
Policyholder B: An average risk profile with 1 CD claim.
Policyholder C: Relatively desirable risk characteristics but eventually had 1 TPL and 2 CD claims during the contract period.

Covariates Only

Covariates + Claim History

Comparison of Cumulative Cashflow

We Have Already Built the Wheels!
Our research group has developed two software packages for LRMoE, which are open-source and readily available for use on real datasets (Tseung et al. 2020) and (Tseung et al. 2021).
It is not difficult to interface with Python via packages like PyJulia (Arakaki et al. 2022) and rpy2 (github repository).